


Nejprve si pro nás laiky ujasněme pojmy. Když se řekne "teranostika"…
Výraz "teranostika" vznikl spojením slov TERApie a diagNOSTIKA. Jedná se o nový termín z odvětví personalizované medicíny, která pomáhá pro pacienty připravovat tzv. léčbu na míru. A to na základě detailního popisu jejich onemocnění, často s využitím genetických analýz.
Každý člověk je posuzován individuálně, protože z pohledu genetické predispozice je jedinečný. Proto se také může lišit jeho reakce na léčebný postup. Díky znalosti genetické informace daného člověka můžeme lépe předpovídat účinnost léčby ještě před podáním léčiva.
O jakých nemocích a jakých léčbách se tu konkrétně bavíme?
Velký význam má personalizovaná medicína například v onkologii. Tam je možné porovnat zárodečnou (tedy dědičnou) genetickou informaci pacienta s genetickou informací v jeho nádorových buňkách, která se navíc v průběhu vývoje nádoru mění. Léčbu tak můžeme cílit přímo na genetické abnormality vyskytující se v nádorových buňkách.
Lék je účinný, ale často ne pro všechny
Je to v Česku či ve světě rozšířený koncept?
Pojem teranostika zatím moc známý není, ale tyto principy se v diagnostice a terapii uplatňují stále častěji. Často se totiž stává, že určitý lék je účinný, ale ne pro všechny pacienty s daným onemocněním. Proto je potřeba vyvinout specifičtější diagnostické metody, které určí, pro kterého pacienta je daný lék vhodný.
V jiných případech mohou existovat diagnostické metody, které od sebe odlišují různé podtypy daného onemocnění - a pro každou takovou skupinu pacientů se volí jiná léčba.

U obou těchto přístupů bývají klíčové právě genetické vlastnosti člověka, ať už vrozené, nebo získané (např. v nádorových buňkách). S tím velmi úzce souvisí rozvoj genomiky a farmakogenomiky, která studuje, jak geny ovlivňují reakci pacienta na aplikaci určitého léku.
Predispozice k nemocem a léková rezistence
Vykazují konkrétně Češi nějaké specifické genetické predispozice, které nás odlišují od ostatních?
Už jen to, jak rychle v těle metabolizujeme některá léčiva, může být u Čechů jiné než u jiných blízkých národů.
Varianty specifické pro Česko byly také pozorovány u některých genetických metabolických poruch, například u familiální hypercholesterolémie a hyperfenylalaninémie.
Rozdíly mezi různými etniky byly popsány také např. u MDR1 genu (gen lékové rezistence), který je významný pro farmakologickou účinnost.
Odlišností je ale celá řada. O mnohých specifických variantách dosud nevíme, protože nám zatím chybí zmíněná databáze variant typických pro českou populaci, kterou chceme v rámci projektu vytvořit.
Co to je familiální hypercholesterolémie a hyperfenylalaninémie - jsou to v Česku častá onemocnění?
Familiální hypercholesterolémie je dědičné onemocnění, při němž je v krvi nadbytek "zlého" cholesterolu. Ve výsledku pak dochází například k předčasným projevům ischemické choroby srdeční. S jedním případem na 200 až 250 jedinců v populaci se jedná o nejčastější vrozené metabolické onemocnění vůbec.
Hyperfenylalaninémie je dědičné onemocnění způsobující zvýšenou hladinu jedné konkrétní aminokyseliny (fenylalaninu) v krvi, což v důsledku může způsobovat třeba poruchy v pigmentaci kůže, zápach moči a v nejhorším případě může být narušen i psychomotorický vývoj. V Česku se každý rok mezi 6 500 novorozenci najde 1 novorozenec s touto nemocí.

A jak jsou na tom Češi se zmíněnou rezistencí vůči lékům?
To, jak na tom v rámci lékové rezistence jsme, lze těžko vyčíslit. I v porovnání s ostatními populacemi jsou efekty různých variant v MDR1 genu těžko interpretovatelné. Nevíme zatím přesně, jak jednotlivé varianty fungují, například jak působí ta, co je četnější v Polsku a co způsobuje naopak ta nejčastější česká.
Nevíme zatím ani to, jak přesně velkým podílem přispívá k celkové lékové rezistenci. Víme jen, že jsme v tomhle v různých zemích světa odlišní. Na lékové rezistenci se však podílí více genů.
Co už naopak víme?
To, že některá léčiva jsou těžko snášenlivá pro lidi s nižší aktivitou genů lékové rezistence. Například digoxin, který se podává pacientům se srdečním selháním, má velmi malé rozpětí mezi terapeutickou a toxickou dávkou.
Bylo zjištěno, že varianta v jedné konkrétní pozici genu MDR1 způsobuje vyšší hladinu digoxinu v krvi oproti lidem bez této varianty, a zmíněnou variantu má zrovna asi 35 % české populace, ale například skoro žádní Poláci.
Kdo je to Čech?
Když se vrátím k databázi, na které pracujete a která bude mapovat genetickou variabilitu české populace. Dá se říct, jak moc jsou Češi geneticky variabilní?
Míru variability naší populace zatím nelze přesně stanovit. Nicméně to, jak jsme variabilní, je vidět už na první pohled. Například i to, jak odlišnou máme barvu vlasů nebo očí, lze označit za genetickou variabilitu.
Podobně variabilní jsme i ve věcech, které na první pohled nevidíme, třeba v už zmíněné reakci na některá léčiva (někdo je zpracovává rychleji než jiný, někdo nereaguje vůbec), jaké máme predispozice k nemocem (například k obezitě či rakovině) nebo jaké máme vlohy (inteligenci nebo talent).
Dá se z hlediska genetiky vůbec popsat, kdo je to Čech?
Na základě populačních dat z České národní genografické databáze víme, že v české populaci jsou nejčastěji zastoupeny genetické profily - tzv. otcovské Y - haplotypy R1a (východoevropský, slovanský), R1b (západoevropský, románský), I2A (jihoslovanský), I1 (skandinávský) nebo E1b1b (středomořský).
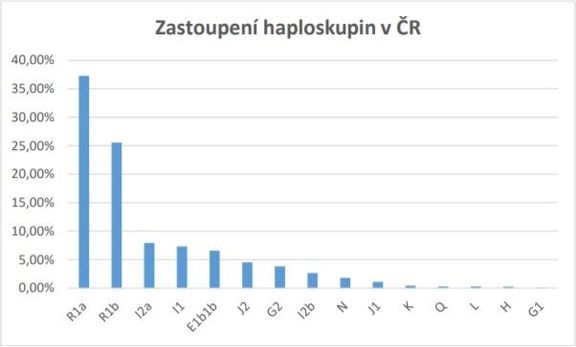
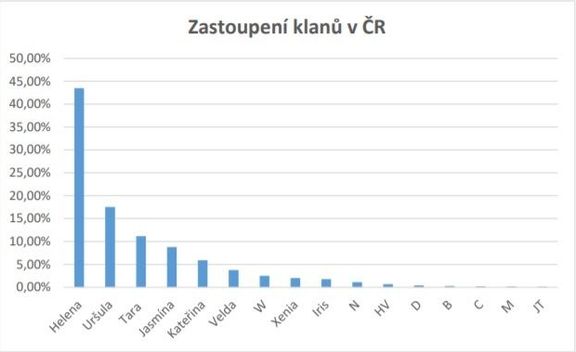
Nejčastější haplotypy děděné po mateřské linii, tzv. Mt- haploskupiny, jsou pak H (Helena), U (Uršula), T (Tara), J (Jasmína) a K (Kateřina). Takže jsme historicky opravdu směsicí z řady různých populací.
Lišíme se v tomto ohledu hodně od okolních států?
Genografická variabilita obyvatel Česka je na rozdíl od ostatních evropských států značná.
Zastoupení osob s typickým slovanským původem (cca 36 %) významně nepřevyšuje nad ostatními, například germánský původ je zastoupen u 25 % Čechů, tři další (jihoslovanský, skandinávský a středomořský) mají zastoupení přibližně po osmi procentech. V našem projektu se budeme při výběru testovaných osob tato zastoupení snažit zachovat.
Okolní státy nemají tak rozmanité zastoupení?
Žádná z našich sousedních ani ostatních evropských zemí nemá tak vyrovnané poměry dvou zcela odlišných haploskupin jako my. Například v Německu převažuje germánská (44,5 %) a druhé dvě nejčastější, slovanská a skandinávská, mají pouze po 16 %.
Ve Francii převládá opět germánská (59 %) a ostatní mají maximálně 8 %. Ve Španělsku je to ještě výraznější, germánská 69 %, druhé dvě nejčastější, skandinávská a středomořská, mají po 8 procentech.

U východoevropských států je situace obdobná, ale s převažující slovanskou haploskupinou. Polsko ji má zastoupenou v 58 % a germánskou pouze ve 12 %. V Rusku je 46 % slovanská haploskupina, jihoslovanská pouze 10 %, na Slovensku je 42 % slovanská haploskupina, a další dvě, germánská a jihoslovanská, po cca 15 %.
Nejrozmanitější jsou například Maďarsko, Bulharsko a Rumunsko, kde se nejvíce vyskytuje slovanská, germánská, jihoslovanská nebo středomořská haploskupina, kdy u žádné z nich však zastoupení nepřesahuje 30 %.
Češi v evropské databázi takřka chybí
Genetické profily už několik let shromažďuje Česká národní genografická databáze, kterou jste už zmínila. Jak se od ní liší vámi vytvářená databáze nová, která pomůže v diagnostikování a stanovování terapie na míru?
Genografické profily jsou zpravidla vytvářeny zkoumáním pouze malého množství konkrétních oblastí lidské DNA. Z celého lidského genomu se pro genografické analýzy přečte jen velmi malý zlomek.
Díky těmto analýzám je pak možné odhadnout původ dávného předka, například jestli má člověk keltské, nebo slovanské kořeny. Z takových informací už ale nejsme obvykle schopni zjistit třeba ony predispozice k nemocem.
V projektu A-C-G-T jde o komplexní analýzu celých lidských genomů včetně všech genů i nekódujících oblastí.
Genografická data z České národní genografické databáze, kterou v roce 2007 založil jeden z našich partnerů projektu Výzkumný ústav Genomac (do dneška nashromáždil více než 7 000 profilů), však budeme využívat při výběru vzorků k sekvenaci, abychom skutečně sekvenovali jedince reprezentativně zastupující českou populaci.
Co bude národní referenční databáze shromažďovat?
- Genom člověka, který je až na výjimky uložen v jádře každé lidské buňky ve formě chromosomů, je tvořen dlouhou dvoušroubovicí DNA sestávající ze 4 typů nukleotidů - zjednodušeně řečeno ze 4 typů písmenek genetické abecedy A - C - G - T (uvedených také v akronymu projektu).
- Genom člověka obsahuje 3,2 miliard těchto písmenek v různém pořadí, které tvoří přibližně 20 tisíc různých genů.
- Cílem projektu je analýza genomů tisíce osob ze všech regionů Česka. Vznikne databáze pozic a frekvencí jednotlivých písmenek (nukleotidů) A, C, G, T na každé pozici v genomu.
- Prakticky pak bude možné říci, že například na 128. pozici se u 80 % osob nachází A a u 20 % G.
Jaká databáze se pro diagnostiku tedy používá v současnosti, když zatím neexistuje přímo její česká varianta?
Řídíme se referenčními daty pro evropskou populaci, nicméně tato databáze je velmi různorodá a Češi v ní téměř nejsou zastoupeni.
Proto nemusí být v molekulárně genetické diagnostice vždy zřejmé, zda nalezená genetické varianta v určité pozici genomu pacienta je patologickou mutací způsobující jeho onemocnění, nebo zda jde pouze o variantu typickou pro naši populaci, která má v jiných populacích menší frekvenci nebo se v nich vůbec nevyskytuje. Databáze vytvořená v rámci A-C-G-T má proto za cíl odhalit specifika české populace.
Takže když to zjednoduším, až to bude díky nové databázi jasnější, bude snazší vyvinout léčiva cílená přímo na Čechy?
V praxi například můžeme zjistit, že v Česku je u určité nemoci častá nějaká konkrétní mutace DNA, a díky tomu zde budou vyvíjeny specifické diagnostické metody a cílená léčiva eliminující škodlivé důsledky nalezené mutace.
Výstupy ze získané databáze budou dostupné a budou využívány jako reference v diagnostice pacientů. Aktuálně jsme ve fázi náboru dobrovolníků, kteří jsou ochotni anonymně poskytnout několik mililitrů své krve pro účely izolace DNA.
Mění se Češi v rámci Evropské unie?
Evropská unie de facto maže mezi jednotlivými členskými státy hranice, volný pohyb osob v Schengenu je samozřejmostí. Do budoucna přitom bude provázanost zemí EU zřejmě ještě větší. Má z tohoto pohledu čistě česká databáze vůbec smysl?
V této provázanosti hraje velkou roli i nadnárodní iniciativa Evropské unie, která si klade za cíl osekvenovat nejméně 1 milion evropských genomů. Do roku 2022 má být zmapováno mnohem více evropských populací, včetně tzv. genomických pouští, tedy oblastí, kde nám informace o lokální genetické variabilitě dosud chybí.
V kooperaci s Českou národní genografickou databází, která neustále mapuje složení obyvatelstva Česka dle původu, pak navíc uvidíme, jak moc se česká populace v čase proměňuje a zda prvních osekvenovaných 1000 českých genomů stále odpovídá původnímu rozložení z let 2019-2022.
Rozhodně se ale počítá s tím, že projekt A-C-G-T je pouze pionýrem českých genomických sekvenačních projektů a v budoucnu se databáze českých genomů bude rozšiřovat. Statisticky pak bude mnohem více odpovídat reálné populaci.
Na projekt Analýza českých genomů pro teranostiku jste v rámci Operačního programu Výzkum, vývoj a vzdělávání získali peníze i z Evropských fondů. Na co přesně putují?
Většina financí je určena na chemikálie, které jsou nutné pro sekvenování 1000 genomů. Stále to ještě není levná záležitost, cena je cca 35 tisíc korun za genom. Velkou část nepochybně tvoří mzdové náklady pro všechny zaměstnance, kteří se podílejí na získávání a zpracovávání vzorků, přípravě biologického materiálu k sekvenaci a na analýze získaných dat.
Jak se můžete do projektu zapojit?
Projekt uvítá zájem dobrovolníků. Pro účast je nutné splnit jen dvě podmínky: věk od 30 do 55 let a původ rodičů z jednoho kraje (aby bylo možné zajistit rovnoměrné pokrytí celé republiky, podle počtů obyvatel v jednotlivých krajích).
V případě zájmu je možno kontaktovat transfuzní oddělení Všeobecné fakultní nemocnice v Praze (U Nemocnice 2, 128 08 Praha 2, pavilon A12, nebo K Interně 640, Praha 5 - Zbraslav), Fakultní nemocnice Brno, Jihlavská 20, nebo Fakultní nemocnice Olomouc, I.P. Pavlova 6.









